
System Architecture
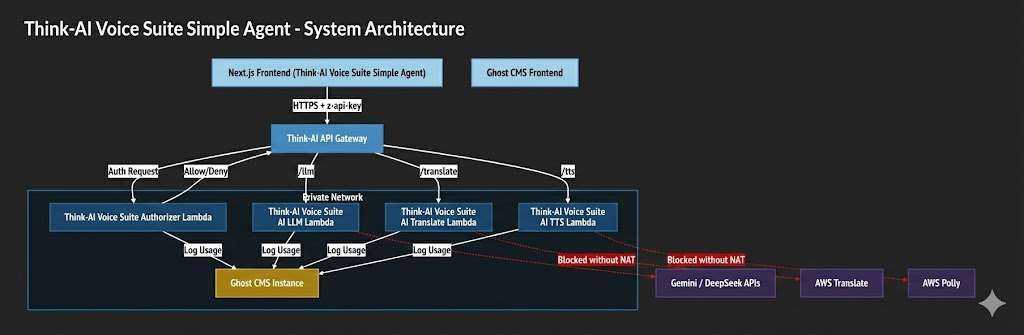
Think-AI's Voice Agent API
Overview
This project provides a serverless API suite for LLM processing, Translation, Text-to-Speech (TTS), and Speech-to-Text (STT) services. It runs on AWS Lambda using a containerized Node.js environment and is exposed via AWS HTTP API Gateway.
1. API Specification
Base URL: https://api.60-think.com (or your API Gateway URL)
Authentication: API Key via Header x-api-key
Authentication
All requests must include the x-api-key header.
-H "x-api-key: <YOUR_CLIENT_API_KEY>"
Endpoints
POST /llm
Process text using various LLM providers (Google Gemini, DeepSeek).
- Request:
{ "task": "expand", // Optional: "expand", "headline" "prompt": "Explain Quantum Computing", "provider": "gemini", // "gemini", "deepseek", "openai" "model": "gemini-2.5-flash", "userId": "1" // For usage logging } - Response:
{ "result": "Quantum computing uses quantum bits...", "provider": "gemini", "model": "gemini-2.5-flash" } - Curl Example:
curl -X POST https://api.60-think.com/llm \ -H "Content-Type: application/json" \ -H "x-api-key: YOUR_KEY" \ -d '{"prompt":"Hello", "provider":"gemini", "userId":"1"}'
POST /translate
Translate text using AWS Translate.
- Request:
{ "text": "Hello, world", "targetLang": "es", // ISO code (ja, es, fr...) "userId": "1" } - Response:
{ "translated": "Hola, mundo" }
POST /tts
Convert text to speech using AWS Polly.
- Request:
{ "text": "Hello world", "voice": "Joanna", // Optional "userId": "1" } - Response:
{ "url": "https://s3.ap-northeast-1.amazonaws.com/your-audio-bucket/tts-....mp3" }
POST /stt/file
Transcribe audio files using AWS Transcribe.
- Request:
{ "fileUrl": "https://example.com/audio.mp3", "language": "en-US", // Optional, default en-US "userId": "1" } - Response:
{ "message": "Job Completed", "jobName": "stt-manual-170...", "transcript": "Hello world from audio..." }
POST /stt/auth
Get temporary AWS credentials for real-time streaming transcription (e.g. from frontend).
- Request:
{ "userId": "1" } - Response:
{ "accessKeyId": "ASIA...", "secretAccessKey": "...", "sessionToken": "...", "region": "ap-northeast-1" }
2. Deployment
Prerequisites
- AWS CLI configured
- Docker installed
.env.productionfile populated
Step 1: Deploy Lambdas (Infrastructure)
Run the setup script to create ECR repos, IAM roles, build the Docker image, and create/update Lambda functions.
./scripts/setup.sh
Step 2: Deploy API Gateway
Run the deploy API script to create or update the HTTP API, routes, integrations, and Authorizer.
./scripts/deploy-api.sh
Step 3: VPC Attachment (Optional/Security)
To attach Lambdas to the VPC (for internal logging privacy):
- Warning: Requires NAT Gateway for external API access (LLM/Translate).
- Run:
./scripts/attach-vpc.sh
Step 4: Update Configuration
To update environment variables without full redeployment:
./scripts/update-config.sh
3. Configuration & Environment Variables
Create a .env.production file with the following keys:
| Variable | Description |
|---|---|
AWS_REGION |
AWS Region (default: ap-northeast-1) |
CLIENT_API_KEY |
Secret key clients must use in x-api-key header |
GEMINI_API_KEY |
API Key for Google Gemini |
DEEPSEEK_API_KEY |
API Key for DeepSeek |
AUDIO_BUCKET |
S3 bucket for TTS audio files |
TRANSCRIPTS_BUCKET |
S3 bucket for STT files |
GHOST_USAGE_API_URL |
URL for Ghost CMS Usage Logging |
GHOST_ADMIN_API_KEY |
Ghost Admin Key for logging auth |
Notes
- Security: The API uses a custom Lambda Authorizer (
ai-authorizer) that validates thex-api-keyheader. - Logging: Usage stats are logged to Ghost CMS. If VPC is enabled, verify internal connectivity.
4. Remote API Verification Report (2026-01-18)
Summary
The ai-voice-suite API was tested against the production environment https://api.60-think.com on 2026-01-18.
The x-api-key authentication is functioning correctly.
Test Results
LLM Providers
| Provider | Model | Status | Notes |
|---|---|---|---|
| DeepSeek | deepseek-chat |
PASS | Response received successfully. |
| GLM | GLM-4 |
PASS | Response received successfully. |
| Gemini | gemini-2.5-flash |
PASS | Response received successfully. |
| Gemini | gemini-3-pro-preview |
PASS (Quota) | Authentication successful, but hit API rate limits (429). |
| Gemini | gemini-2.5-flash-image (Nano) |
PASS (Quota) | Authentication successful, but hit API rate limits (429). |
| Gemini | veo-3.0-generate-001 |
FAIL | Model requires predictLongRunning method, which is not yet supported. |
Other Endpoints
| Endpoint | Function | Status | Notes |
|---|---|---|---|
/translate |
AWS Translate | PASS | Text translated successfully. |
/tts |
AWS Polly | PASS | Audio URL generated. |
/stt/file |
AWS Transcribe | PASS | Job started. |
/webhook |
Ghost Webhook | PASS | Webhook processed. |
API Test
API Test Summary
Date: Sat Jan 17 22:30:30 JST 2026
API URL: https://api.60-think.com
Test: Unauthorized Access
Endpoint: /llm
Response (No Header):
{"message":"Unauthorized"}
Test: llm-deepseek
Endpoint: /llm
Payload:
{
"task": "expand",
"prompt": "Explain the concept of recursion.",
"provider": "deepseek",
"model": "deepseek-chat",
"userId": "1"
}
Response:
{"error":"[GoogleGenerativeAI Error]: Error fetching from https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent: fetch failed"}
Duration: 10945ms
Test: llm-nano
Endpoint: /llm
Payload:
{
"task": "expand",
"prompt": "Describe a sunset.",
"provider": "gemini",
"model": "gemini-2.5-flash-image",
"userId": "1"
}
Response:
{"message":"Service Unavailable"}
Duration: 30232ms
Test: tts
Endpoint: /tts
Payload:
{
"text": "This is a test of the audio system.",
"voice": "Joanna",
"userId": "1"
}
Response:
{"error":"[GoogleGenerativeAI Error]: Error fetching from https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent: fetch failed"}
Duration: 11683ms
Test: llm-veo
Endpoint: /llm
Payload:
{
"task": "expand",
"prompt": "A cat playing piano.",
"provider": "gemini",
"model": "veo-3.0-generate-001",
"userId": "1"
}
Response:
{"message":"Service Unavailable"}
Duration: 30175ms
Test: llm-gemini-flash
Endpoint: /llm
Payload:
{
"task": "expand",
"prompt": "List 3 programming languages.",
"provider": "gemini",
"model": "gemini-2.5-flash",
"userId": "1"
}
Response:
{"error":"[GoogleGenerativeAI Error]: Error fetching from https://generativelanguage.googleapis.com/v1beta/models/veo-3.0-generate-001:generateContent: fetch failed"}
Duration: 9989ms
Test: llm
Endpoint: /llm
Payload:
{
"task": "expand",
"prompt": "Tell me a joke about APIs",
"provider": "gemini",
"model": "gemini-2.5-flash",
"userId": "1"
}
Response:
{"error":"[GoogleGenerativeAI Error]: Error fetching from https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent: fetch failed"}
Duration: 10800ms
Test: llm-gemini-pro
Endpoint: /llm
Payload:
{
"task": "expand",
"prompt": "Describe the future of AI.",
"provider": "gemini",
"model": "gemini-3-pro-preview",
"userId": "1"
}
Response:
{"error":"[GoogleGenerativeAI Error]: Error fetching from https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent: fetch failed"}
Duration: 10028ms
Test: translate
Endpoint: /translate
Payload:
{
"text": "Sixty years of experiences, countless stories. This is your exclusive platform to share life wisdom and relive wonderful legends.",
"source": "en",
"target": "ja",
"userId": "1"
}
Response:
{"message":"Service Unavailable"}
Duration: 30277ms
Test: stt
Endpoint: /stt/file
Payload:
{
"fileUrl": "https://dnicugzydez8x.cloudfront.net/60-think-prd/2025/11/speech_20251105082319224.mp3",
"language": "zh-CN",
"userId": "1"
}
Response:
{"error":"[GoogleGenerativeAI Error]: Error fetching from https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent: fetch failed"}
Duration: 11869ms
Test: llm-nano
Endpoint: /llm
Payload:
{
"task": "expand",
"prompt": "Describe a sunset.",
"provider": "gemini",
"model": "gemini-2.5-flash-image",
"userId": "1"
}
Response:
{"error":"[GoogleGenerativeAI Error]: Error fetching from https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent: fetch failed"}
Duration: 10163ms
Test: llm-veo
Endpoint: /llm
Payload:
{
"task": "expand",
"prompt": "A cat playing piano.",
"provider": "gemini",
"model": "veo-3.0-generate-001",
"userId": "1"
}
Response:
{"message":"Service Unavailable"}
Duration: 30553ms
Test: tts
Endpoint: /tts
Payload:
{
"text": "This is a test of the audio system.",
"voice": "Joanna",
"userId": "1"
}
Response:
{"error":"[GoogleGenerativeAI Error]: Error fetching from https://generativelanguage.googleapis.com/v1beta/models/veo-3.0-generate-001:generateContent: fetch failed"}
Duration: 10160ms
Test: llm
Endpoint: /llm
Payload:
{
"task": "expand",
"prompt": "Tell me a joke about APIs",
"provider": "gemini",
"model": "gemini-2.5-flash",
"userId": "1"
}
Response:
{"message":"Service Unavailable"}
Duration: 30283ms
Test: webhook
Endpoint: /webhook
Payload:
{
"post": {
"current": {
"title": "New Blog Post",
"html": "<p>Content with audio need.</p>"
}
}
}
Response:
{"error":"[GoogleGenerativeAI Error]: Error fetching from https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent: fetch failed"}
Duration: 11589ms
Test: translate
Endpoint: /translate
Payload:
{
"text": "Sixty years of experiences, countless stories. This is your exclusive platform to share life wisdom and relive wonderful legends.",
"source": "en",
"target": "ja",
"userId": "1"
}
Response:
{"message":"Service Unavailable"}
Duration: 30135ms
Test: stt
Endpoint: /stt/file
Payload:
{
"fileUrl": "https://dnicugzydez8x.cloudfront.net/60-think-prd/2025/11/speech_20251105082319224.mp3",
"language": "zh-CN",
"userId": "1"
}
Response:
{"message":"Service Unavailable"}
Duration: 28637ms
Response:
{"message":"Service Unavailable"}
Duration: 30276ms
Test: tts
Endpoint: /tts
Payload:
{
"text": "This is a test of the audio system.",
"voice": "Joanna",
"userId": "1"
}
Response:
{"message":"Service Unavailable"}
Duration: 30258ms
Test: webhook
Endpoint: /webhook
Payload:
{
"post": {
"current": {
"title": "New Blog Post",
"html": "<p>Content with audio need.</p>"
}
}
}
Response:
{"message":"Service Unavailable"}
Duration: 28637ms
Test: stt
Endpoint: /stt/file
Payload:
{
"fileUrl": "https://dnicugzydez8x.cloudfront.net/60-think-prd/2025/11/speech_20251105082319224.mp3",
"language": "zh-CN",
"userId": "1"
}
Response:
{"message":"Service Unavailable"}
Duration: 30501ms
Response:
{"message":"Service Unavailable"}
Duration: 30316ms
Test: webhook
Endpoint: /webhook
Payload:
{
"post": {
"current": {
"title": "New Blog Post",
"html": "<p>Content with audio need.</p>"
}
}
}
Response:
{"message":"Service Unavailable"}