2025/11/05
音声対応とサービス
Like
0
Bookmark
0
Forward

タロウ
日本 北海道 札幌市
タロウ
日本 北海道 札幌市
①
テキスト読み上げ(TTS)比較表
| サービス | タイプ | 長所 | 最適な用途 | 価格モデル |
|---|---|---|---|---|
| OpenAI TTS | クラウドAPI | 最も自然で表現豊かな音声 | オーディオブック、AIアシスタント | 従量課金 |
| Amazon Polly | クラウドAPI | 多言語対応、企業向け機能 | 企業システム、AWS連携 | 従量課金(無料枠あり) |
| Google Cloud TTS | クラウドAPI | カスタム音声作成、高品質 | ブランド音声が必要な案件 | 従量課金(無料枠あり) |
| ElevenLabs | クラウドAPI | 優秀な音声クローン、感情表現 | コンテンツ制作、ゲーム・動画 | フリーミウム |
| Coqui TTS | オープンソース | カスタマイズ性、オフライン実行 | 研究、プライバシー重視 | 無料 |
音声認識(STT)比較表
| サービス | タイプ | 長所 | 最適な用途 | 価格モデル |
|---|---|---|---|---|
| OpenAI Whisper API | クラウドAPI | 最高精度、多言語対応 | 一般的な文字起こし、翻訳 | 従量課金 |
| Google Speech-to-Text | クラウドAPI | 話者分離、専門分野対応 | 会議議事録、電話対応 | 従量課金(無料枠あり) |
| AssemblyAI | クラウドAPI | 感情分析、コンテンツモデレーション | 音声分析、高度な処理 | 従量課金(無料枠あり) |
| OpenAI Whisper | オープンソース | 高精度、オフライン実行 | プライバシー重視、予算制限 | 無料 |
簡単な選択ガイド
テキスト読み上げ(TTS):
- 最高品質: OpenAI TTS または ElevenLabs
- 企業向け: Amazon Polly または Google TTS
- 無料/オフライン: Coqui TTS
音声認識(STT):
- 最高精度: OpenAI Whisper API
- 会議解析: Google Speech-to-Text
- 無料/オフライン: オープンソースWhisper
ご自身の予算、実行環境、品質要件に合わせて最適なものを選んでください!
②
音声認識(Speech-to-Text: STT)
1. Google Cloud Speech-to-Text
- 特長:高精度、125言語以上対応、リアルタイムストリーミング、句読点の自動挿入、話者分離(diarization)機能あり。
- おすすめ用途:汎用的なエンタープライズアプリケーション、多言語対応が必要なサービス。
- 価格:従量課金制。無料枠あり。
- 備考:2023年にリリースされた「Chirp」モデルにより、騒音下での認識精度がさらに向上。
2. OpenAI Whisper(オープンソース)
- 特長:オープンソースで99言語対応。さまざまな訛りや雑音下でも高い性能。
- おすすめ用途:オフライン/オンプレミス処理、研究、カスタムファインチューニングが必要な開発者。
- モデルサイズ:
whisper-tinyからwhisper-large-v3(高精度)まであり。 - 欠点:計算リソースを多く消費するため、レイテンシがクラウドAPIより高め。
3. AssemblyAI
- 特長:高精度な文字起こしに加え、要約、感情分析、個人情報(PII)のマスキングなどのAI機能も豊富。
- おすすめ用途:ポッドキャスト/動画のトランスクリプション、カスタマーサポート解析。
- 精度:クリーンな音声では人間並みの精度。
4. Deepgram
- 特長:低レイテンシのリアルタイム音声認識。開発者フレンドリー。ドメイン固有語彙へのカスタムモデル学習も可能。
- おすすめ用途:コールセンターやライブ音声処理など、即時性が求められるアプリケーション。
5. Amazon Transcribe
- 特長:AWSエコシステムとの親和性が高く、カスタム語彙や医療/法務向け専門モデルも提供。
- おすすめ用途:AWS中心のインフラでの導入。
テキスト読み上げ(Text-to-Speech: TTS)
1. ElevenLabs
- 特長:非常に自然で感情豊かな音声。感情の表現や音声クローン、多言語対応も可能。
- おすすめ用途:クリエイティブコンテンツ、オーディオブック、チャットボット、高品質な音声合成。
- API:使いやすく、リアルタイムストリーミングにも対応。
- 備考:2025年時点で自然さの分野で業界トップクラス。
2. Google Cloud Text-to-Speech
- 特長:WaveNet音声(非常に自然)、50言語以上で300以上の音声を提供。
- おすすめ用途:エンタープライズアプリケーション、多言語対応、Googleサービスとの統合。
3. Amazon Polly
- 特長:ニューラルTTS(NTTS)搭載、SSML対応、ナチュラルな音声。AWSとの統合が容易。
- おすすめ用途:IVR(自動音声応答)、eラーニング、アクセシビリティ支援ツール。
4. Microsoft Azure Cognitive Services(Speech Service)
- 特長:高品質なニューラル音声、カスタム音声作成機能、エンタープライズ向け機能が充実。
- おすすめ用途:Microsoftエコシステム利用者、多言語カスタマーサポートボット。
5. Coqui TTS(オープンソース)
- 特長:完全オープンソース。音声クローンやオフライン利用が可能。
- おすすめ用途:プライバシー重視・オンデバイス処理が必要なケース。
- 欠点:技術的なセットアップが必要。商用APIと比べると自然さはやや劣る。
用途別おすすめ一覧
汎用・多言語対応 | Google Speech-to-Text | Google TTS または ElevenLabs |
最高の自然さ(TTS) | — | ElevenLabs |
オフライン/オープンソース | Whisper | Coqui TTSまたはTortoise-TTS |
リアルタイム会話 | Deepgram または AssemblyAI | ElevenLabs(ストリーミング対応) |
エンタープライズ/コンプライアンス重視 | Amazon Transcribe または Google STT | Azure TTS または Amazon Polly |
コンテンツ分析(STT+AI機能) | AssemblyAI | — |
最後にアドバイス:
- プロトタイピング段階:ElevenLabs と Whisper(無料枠またはオープンソース版あり)がおすすめ。
- 本番環境・大規模運用:信頼性とサポート面で Google、Azure、AWS が適しています。
- プライバシー重視・オンデバイス処理:Whisper(STT)+ Coqui TTS(TTS)の組み合わせ。
具体的な用途(例:リアルタイムチャットボット、オーディオブック制作、コールセンターの音声解析など)を教えていただければ、さらに最適な選択肢をご提案できます!
ElevenLabs and price
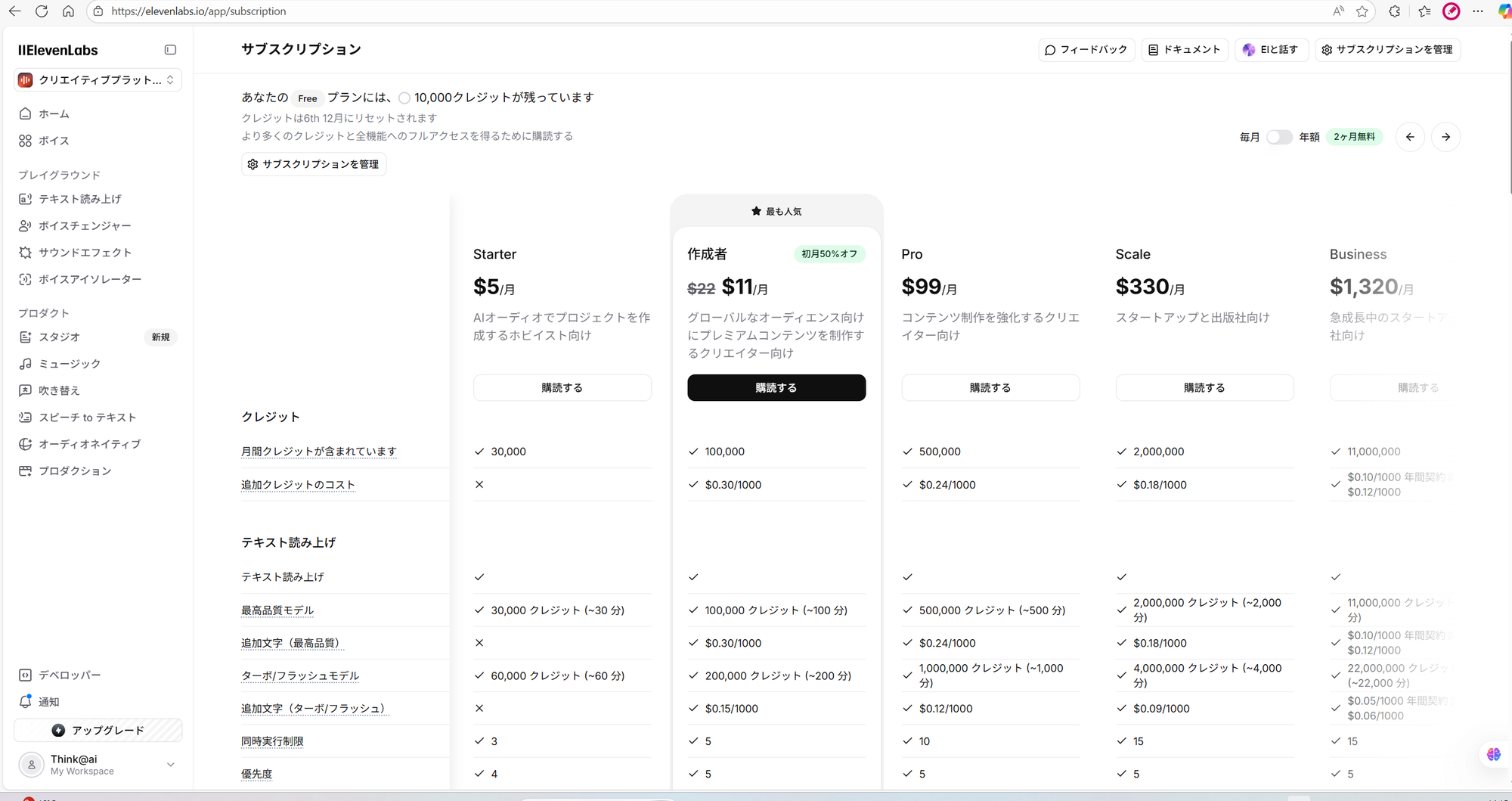
https://elevenlabs.io/app/voice-library (機能豊富、ただ、中国語。。)
AWS Polly TTS, AWS Transcribe, Translate (使いやすい、AWS環境と統合)
https://beyondwords.io/integrations/ (CMS統合あり)
针对需要同时支持日语、英语和中文的语音模型,我将从开源和商业API两个维度为您梳理推荐。
日英中三语支持模型概览
| 类别 | 模型/平台 | 提供商 | 日英中支持情况 | 核心特点 |
|---|---|---|---|---|
| 🈲 语音识别 (ASR) | OpenAI Whisper | OpenAI | ✅ 优秀 | 开源标杆,在多种语言和口音上表现强劲,特别适合日语和中文的混合场景。 |
| Qwen2-Audio / Qwen3-ASR | 阿里巴巴 | ✅ 优秀 | 原生支持多语言混合识别,在日语、中文及带口音英语上表现突出。 | |
| FunASR | 阿里巴巴 | ✅ 良好 | 工业级开源模型,对中文有深度优化,同时支持日语和英语。 | |
| Azure Speech to Text | 微软 | ✅ 优秀 | 成熟的商业API,支持实时转录和批量处理,语言切换智能。 | |
| Amazon Transcribe | AWS | ✅ 优秀 | 企业级服务,与AWS生态无缝集成,支持自定义模型优化。 | |
| Google Speech-to-Text | 谷歌 | ✅ 优秀 | 老牌服务,准确率高,支持长音频和嘈杂环境。 | |
| 🎵 语音合成 (TTS) | OpenAI TTS | OpenAI | ✅ 优秀 | 音质自然度领先,提供tts-1(快速)和tts-1-hd(高清)两种模型。 |
| CosyVoice | 阿里巴巴 | ✅ 良好 | 开源方案,支持多语言和声音复刻,情感表现好。 | |
| Azure Text to Speech | 微软 | ✅ 优秀 | 音色库极其丰富,提供多种日语、中文和英语音色,支持细粒度调节。 | |
| Amazon Polly | AWS | ✅ 优秀 | 提供“神经TTS”,音质自然,包含专门的日语(Mizuki, Takumi)和中文(Zhiyu)音色。 | |
| Google Cloud TTS | 谷歌 | ✅ 优秀 | WaveNet技术,音质出色,语言和音色选择多。 |
💡 如何选择?
您可以根据您的核心需求,参考以下决策路径来快速筛选:
1. 如果您追求极致的准确率和易用性,且预算充足:
- 语音识别 (ASR):首选 OpenAI Whisper API 或 微软 Azure Speech。它们在三语混合场景下的准确率和鲁棒性经过了广泛验证。
- 语音合成 (TTS):首选 OpenAI TTS 或 微软 Azure TTS。OpenAI TTS的自然度目前广受好评,而Azure提供了最丰富的音色选择。
2. 如果您在AWS或Google Cloud生态内:
- 直接使用 Amazon Transcribe & Polly 或 Google Speech-to-Text & TTS 是最高效的选择,集成方便,服务稳定。
3. 如果您注重数据隐私、成本可控或需要深度定制:
- 语音识别 (ASR):OpenAI Whisper(开源版)是不二之选,可以部署在本地服务器。
- 语音合成 (TTS):CosyVoice 是一个优秀的全栈式开源方案,支持多语言和声音克隆。
4. 如果您希望使用国产技术栈:
- 阿里的 Qwen2-Audio 和 CosyVoice 组合提供了一个从识别到合成的、支持多语言的完整开源方案,潜力巨大,值得尝试。
🚀 下一步行动建议
- 商业API:大部分都提供免费试用额度,强烈建议用您的实际业务数据(特别是包含三种语言的音频/文本)去测试不同服务商的效果。
- 开源模型:访问其GitHub仓库,按照文档在本地或测试环境进行部署和效果评估,重点关注推理速度和资源消耗。
ElevenLabs 是一个非常出色且特点鲜明的AI语音合成平台,在特定领域可以说是行业标杆。我来为你全面分析一下它的优缺点和适用场景。
🌟 核心优势
1. 顶级的语音自然度和表现力
- 情感表达:ElevenLabs生成的语音在情感起伏、语调变化和自然停顿方面远超多数竞争对手。
- 人性化程度:听起来几乎不像AI,避免了常见的“机器人腔调”。
2. 强大的声音克隆功能
- 仅需1分钟音频就能克隆一个声音,效果惊人地好。
- 高质量克隆:如果提供更长的清晰音频(3-10分钟),克隆效果会更加精准。
3. 优秀的多语言支持
- 虽然主打英语,但对日语、中文等其他语言的支持也在不断改进,效果相当不错。
4. 用户友好的界面和API
- 网页界面直观易用
- API文档清晰,集成相对简单
⚠️ 需要注意的方面
1. 定价策略
python# 价格相对较高,特别是对于:
- 高用量项目
- 商业用途
- 需要大量声音克隆的场景
免费额度有限,超出后需要付费。
2. 语言支持的细节
- 虽然在英语上表现极致优秀
- 但在日语、中文等语言上,与母语模型相比可能还有细微差距
- 发音准确度很高,但地道的语感表达还有提升空间
3. 声音克隆的伦理风险
- 容易被滥用进行深度伪造
- 平台有一些防护措施,但仍需谨慎使用
🎯 最适合的使用场景
✅ 强烈推荐用于:
- 创意内容制作:YouTube视频、播客、有声书
- 游戏开发:为NPC角色生成对话
- 动画和虚拟偶像:角色语音生成
- AI助手和聊天机器人:追求极致自然对话体验
- 个人项目:想要快速获得高质量语音
❌ 不太适合:
- 预算极其有限的项目
- 需要完全离线部署的场景
- 仅需要基础TTS功能的简单应用
🔄 与其他服务的对比
| 特性 | ElevenLabs | 传统TTS服务 | 开源方案 |
|---|---|---|---|
| 自然度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| 声音克隆 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| 多语言 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ |
| 价格 | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 易用性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ |
💡 我的使用建议
- 先试用免费额度:用你的日文、英文、中文内容测试效果
- 重点关注:
- 日语发音的自然程度
- 英语的情感表达
- 中文的声调准确性
- 如果预算允许,ElevenLabs在创意内容制作方面几乎是无敌的
🚀 下一步行动
推荐你这样开始:
- 访问 ElevenLabs 官网注册账号
- 使用免费额度测试你的三语内容
- 如果效果满意,考虑从创作者套餐开始
一句话总结: 如果你追求极致的语音质量和强大的声音克隆,且预算不是主要限制,ElevenLabs绝对是首选。但如果只是需要基础的多语言TTS功能,可能有更经济的选择。
Like
0
Bookmark
0
Forward